

In New York in 1997, the reigning world chess champion Garry Kasparov faced off against Deep Blue, a computer specially designed by IBM to beat him. Following a similar match in Philadelphia the previous year, which Kasparov won 4–2, the man widely regarded as the greatest chess player of all time was confident of victory. When he lost, he claimed some of Deep Blue’s moves were so intelligent and creative that they must have been the result of human intervention. But we understand why Deep Blue made those moves: its process for selecting them was ultimately one of brute force, a massively parallel architecture of 14,000 custom-designed chess chips, capable of analysing 200 million board positions per second. At the time of the match, it was the 259th most powerful computer on the planet, and it was dedicated purely to chess. It could simply hold more outcomes in mind when choosing where to play next. Kasparov was not outthought, merely outgunned.
By contrast, when the Google Brain–powered AlphaGo software defeated the Korean Go professional Lee Sedol, one of the highest-rated players in the world, something had changed. In the second of five games, AlphaGo played a move that stunned Sedol and spectators alike, placing one of its stones on the far side of the board, and seeming to abandon the battle in progress. “That’s a very strange move,” said one commentator. “I thought it was a mistake,” said the other. Fan Hui, another seasoned Go player who had been the first professional to lose to the machine six months earlier, said of it: “It’s not a human move. I’ve never seen a human play this move.” And he added, “So beautiful.” In the history of the 2,500-year-old game, nobody had ever played like this. AlphaGo went on to win the game, and the series.
AlphaGo’s engineers developed its software by feeding a neural network millions of moves by expert Go players, and then getting it to play itself millions of times more, developing strategies that outstripped those of human players. But its own representation of those strategies is illegible: we can see the moves it made, but not how it decided to make them. The sophistication of the moves that must have been played in those games between the shards of AlphaGo is beyond imagination, too, but we are unlikely to ever see and appreciate them; there’s no way to quantify sophistication, only winning instinct.
The late and much-lamented Iain M. Banks called the place where these moves occurred ‘Infinite Fun Space’. In Banks’s sci-fi novels, his Culture civilisation is administered by benevolent, superintelligent AIs called simply Minds. While the Minds were originally created by humans (or, at least, some biological, carbon-based entities), they have long since outstripped their creators, redesigned and rebuilt themselves, and become both inscrutable and all-powerful. Between controlling ships and planets, directing wars, and caring for billions of humans, the Minds also take up their own pleasures, which involve speculative computations beyond the comprehension of humankind. Capable of simulating entire universes within their imaginations, some Minds retreat forever into Infinite Fun Space, a realm of meta-mathematical possibility, accessible only to superhuman artificial intelligences. And the rest of us, if we spurn the arcade, are left with Finite Fun, fruitlessly analysing the decisions of machines beyond our comprehension.
Some operations of machine intelligence do not stay within Infinite Fun Space however. Instead, they create an unknowingness in the world: new images; new faces; new, unknown, or false events. The same approach by which language can be cast as an infinite mesh of alien meaning can be applied to anything that can be described mathematically – that is, as a web of weighted connections in multidimensional space. Words drawn from human bodies still have relationships, even when shorn of human meaning, and calculations can be performed upon the number of that meaning. In a semantic network, the lines of force – vectors – that define the word ‘queen’ align with those read in the order ‘king – man + woman’. The network can infer a gendered relationship between ‘king’ and ‘queen’ by following the path of such vectors. And it can do the same thing with faces.
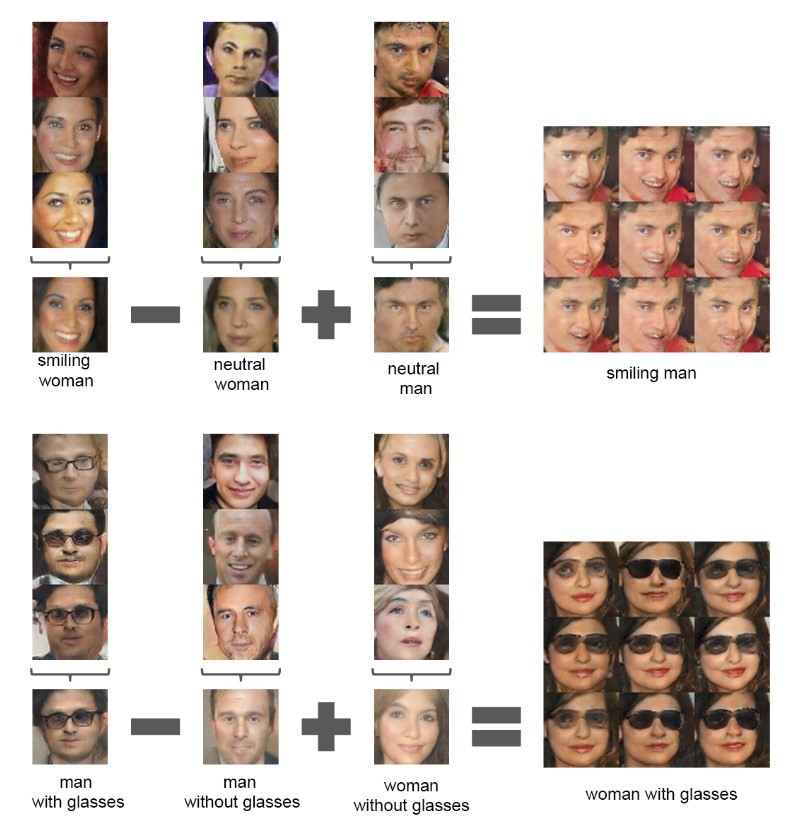
Given a set of images of people, a neural network can perform calculations that do not merely follow these lines of force, but generate new outcomes. A set of photographs of smiling women, unsmiling women and unsmiling men can be computed to produce entirely new images of smiling men, as shown in a paper published by Facebook researchers in 2015. In the same paper, the researchers generate a range of new images. Using a dataset of more than three million photographs of bedrooms from a large-scale image recognition challenge, their network generates new bedrooms: arrangements of colour and furniture that have never existed in the real world, but come into being at the intersection of vectors of bedroomness: walls, windows, duvets and pillows. Machines dreaming dream rooms where no dreams are dreamed. But it is the faces – anthropomorphs that we are – that stick in the mind: Who are these people, and what are they smiling at?
Things get stranger still when these dream images start to interleave with our own memories. Robert Elliott Smith, an artificial intelligence researcher at University College London, returned from a family holiday in France in 2014 with a phone full of photos. He uploaded a number of them to Google+, to share them with his wife, but while browsing through them he noticed an anomaly. In one image, he saw himself and his wife at a table in a restaurant, both smiling at the camera. But this photograph had never been taken. At lunch one day, his father had held the button down on his iPhone a little long, resulting in a burst of images of the same scene. Smith uploaded two of them, to see which his wife preferred. In one, he was smiling, but his wife was not; in the other, his wife was smiling, but he was not. From these two images, taken seconds apart, Google’s photo-sorting algorithms had conjured a third: a composite in which both subjects were smiling their ‘best’. The algorithm was part of a package called AutoAwesome (since renamed, simply, ‘Assistant’), which performed a range of tweaks on uploaded images to make them more ‘awesome’ – applying nostalgic filters, turning them into charming animations, and so forth. But in this case, the result was a photograph of a moment that had never happened: a false memory, a rewriting of history.
The doctoring of photographs is an activity as old as the medium itself, but in this case the operation was being performed automatically and invisibly on the artefacts of personal memory. And yet, perhaps there is something to learn from this too: the delayed revelation that images are always false, artificial snapshots of moments that have never existed as singularities, forced from the multidimensional flow of time itself. Unreliable documents; composites of camera and attention. They are artefacts not of the world and of experience, but of the recording process – which, as a false mechanism, can never approach reality itself. It is only when these processes of capture and storage are reified in technology that we are able to perceive their falsity, their alienation from reality. This is the lesson that we might draw from the dreams of machines: not that they are rewriting history, but that history is not something that can be reliably narrativised; and thus, neither can the future. The photographs mapped from the vectors of artificial intelligence constitute not a record but an ongoing reimagining, an ever-shifting set of possibilities of what might have been and what is to come. This cloud of possibility, forever contingent and nebulous, is a better model of reality than any material assertion. This cloud is what is revealed by the technology.
This illumination of our own unconscious by the machines is perhaps best illustrated by another weird output from Google’s machine learning research: a programme called DeepDream. DeepDream was designed to better illuminate the internal workings of inscrutable neural networks. In order to learn to recognise objects, a network was fed millions of labelled images of things: trees, cars, animals, houses. When exposed to a new image, the system filtered, stretched, tore and compressed the image through the network in order to classify it: this is a tree, a car, an animal, a house. But DeepDream reversed the process: by feeding an image into the back end of the network, and activating the neurons trained to see particular objects, it asked not what is this image, but what does the network want to see in it? The process is akin to that of seeing faces in clouds: the visual cortex, desperate for stimulation, assembles meaningful patterns from noise.
DeepDream’s engineer, Alexander Mordvintsev, created the first iteration of the programme at two in the morning, having been woken by a nightmare. The first image he fed into the system was of a kitten sat on a tree stump, and the output was a nightmare monster all its own: a hybrid cat/dog with multiple sets of eyes, and wet noses for feet. When Google first released an untrained classifier network on ten million random YouTube videos in 2012, the first thing it learned to see, without prompting, was a cat’s face: the spirit animal of the internet. Mordvintsev’s network thus dreamed of what it knew, which was more cats and dogs. Further iterations produced Boschian hellscapes of infinite architecture, including arches, pagodas, bridges, and towers in infinite, fractal progressions, according to the neurons activated. But the one constant that recurs throughout DeepDream’s creations is the image of the eye – dogs’ eyes, cats’ eyes, human eyes; the omnipresent, surveillant eye of the network itself. The eye that floats in DeepDream’s skies recalls the all-seeing eye of dystopian propaganda: Google’s own unconscious, composed of our memories and actions, processed by constant analysis and tracked for corporate profit and private intelligence. DeepDream is an inherently paranoid machine because it emerges from a paranoid world.
Meanwhile, when not being forced to visualise their dreams for our illumination, the machines progress further into their own imaginary space, to places we cannot enter. Walter Benjamin’s greatest wish, in The Task of the Translator, was that the process of transmission between languages would invoke a “pure language” – an amalgam of all the languages in the world. It is this aggregate language that is the medium in which the translator should work, because what it reveals is not the meaning but the original’s manner of thinking. Following the activation of Google Translate’s neural network in 2016, researchers realised that the system was capable of translating not merely between languages, but across them; that is, it could translate directly between two languages it had never seen explicitly compared. For example, a network trained on Japanese–English and English–Korean examples is capable of generating Japanese–Korean translations without ever passing through English. This is called ‘zero-shot’ translation, and what it implies is the existence of an ‘interlingual’ representation: an internal metalanguage composed of shared concepts across languages.
This is, to all intents, Benjamin’s pure language; it is the meaningless metalanguage of the arcade. By visualising the architecture of the network and its vectors as splashes of colour and line, it’s possible to see sentences in multiple languages clustered together. The outcome is a semantic representation evolved by, not designed into, the network. But this is as close as we shall ever get, for once again, we are peering through the window of Infinite Fun Land – an arcade we will never get to visit.

